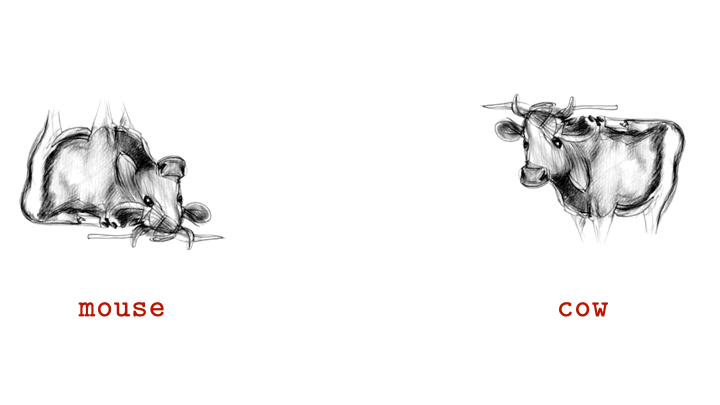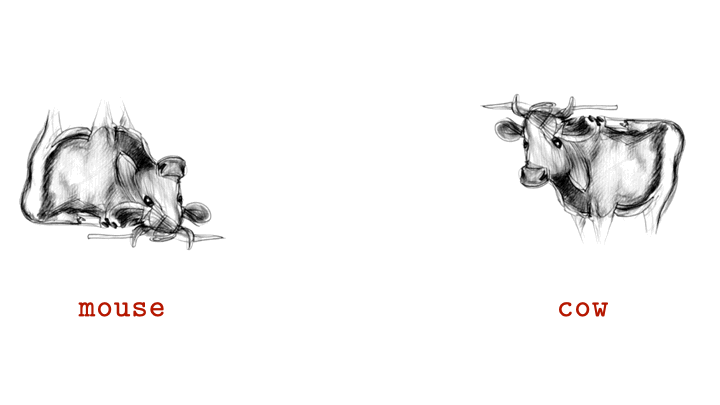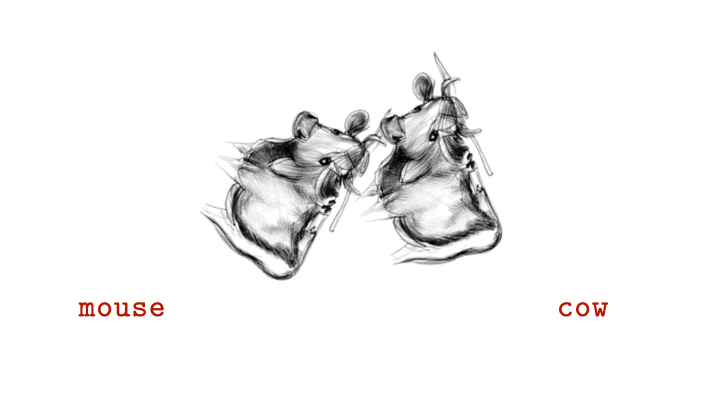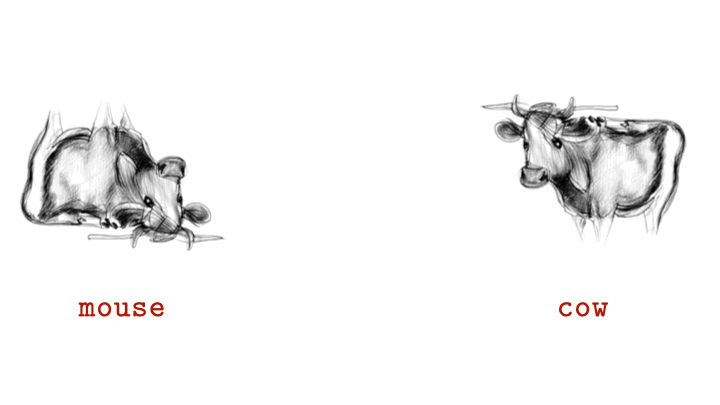
Researchers at Johns Hopkins University have unveiled a remarkable new form of AI-generated imagery called “visual anagrams.” These are single images that appear as completely different objects when rotated, offering scientists a powerful new way to study how the human brain interprets visual information.
Unlike traditional illusions or ambiguous images, visual anagrams are created using advanced generative AI models that ensure both versions of the image share identical pixels. The only difference is orientation — a 180-degree rotation can turn one recognizable object into another.
This breakthrough allows researchers to explore how perception, emotion, and recognition can change even when the raw visual data stays exactly the same.
How Visual Anagrams Work
Each visual anagram is produced by feeding AI models carefully designed prompts that balance two distinct visual identities within one structure. When viewed upright, the image may depict, for example, a cat; when flipped, it could reveal a human face or bird — all without altering color, lighting, or texture.
By holding constant the underlying pixels, scientists can isolate the cognitive processes involved in perception. This allows them to ask new kinds of questions:
- How does the brain decide what it’s seeing?
- Why do emotions change based on orientation?
- What cues make us perceive life, motion, or animacy in static objects?
These are questions that, until now, have been difficult to study without confounding factors such as shape or color differences between stimuli.
A Tool for Studying Emotion, Animacy, and Object Identity
The Johns Hopkins team found that when participants viewed these AI-generated images, their emotional and perceptual responses shifted dramatically depending on which orientation they saw first — even though every pixel was identical.
For example, an image might evoke warmth and empathy in one position, but appear eerie or unsettling when rotated. This suggests that orientation alone can influence how the human brain interprets emotion and animacy.
The implications extend far beyond academic curiosity. The research could inform future studies in neuroscience, psychology, and AI vision systems, offering a standardized method to test how humans and machines interpret ambiguous visual data.
Why It Matters
Visual anagrams represent a new way to probe the mechanics of perception — bridging art, artificial intelligence, and neuroscience. By stripping away visual distractions, researchers can focus purely on how the brain constructs meaning from identical inputs.
This method could help scientists:
- Build better models of how humans recognize faces or objects.
- Understand how emotions attach to certain visual cues.
- Train AI systems to mimic — or better interpret — human perception.
Ultimately, these findings reveal just how flexible and interpretive human vision truly is. Even with the same pixels, the mind can tell two entirely different stories.
The Future of AI and Visual Cognition
The creation of visual anagrams is part of a broader movement to use AI not only as a creative tool but as a scientific instrument. As generative models grow more sophisticated, researchers can now design tightly controlled visual experiments that were previously impossible.
By blending computational creativity with human psychology, the Johns Hopkins study opens a path toward understanding one of science’s deepest mysteries — how the brain turns patterns of light into perception, meaning, and emotion.

