Large Language Models (LLMs) like GPT and Mistral have transformed artificial intelligence, but their enormous computational demands create significant energy and speed bottlenecks. A groundbreaking new study published in Nature Computational Science presents a revolutionary hardware solution that could change everything – delivering up to 100x faster processing and 10,000x better energy efficiency for attention mechanisms in LLMs.
The Current Challenge: Memory Transfer Bottlenecks
Traditional GPU-based LLM inference faces a critical problem: the attention mechanism requires constantly transferring massive amounts of data between main memory and cache memory. In generative transformers, self-attention uses cache memory to store token projections, avoiding recomputation at each time step. However, graphics processing unit (GPU)-stored projections must be loaded into static random-access memory for each new generation step, causing latency and energy bottlenecks.
For context, the KV cache for a model like Mistral 7B requires 8 GB of memory for a single batch, and this data must be constantly shuttled back and forth during inference. In recent technologies, the energy for data access exceeds the energy required for computations. Loading the KV cache for the attention mechanism is thus a major bottleneck, causing increased energy consumption and latency in large language models.
The Breakthrough: Analog In-Memory Computing with Gain Cells
Researchers from multiple institutions have developed an innovative solution using specialized analog memory devices called “gain cells” that can both store data and perform computations directly within the memory itself. This eliminates the need for constant data transfer between different memory types.
Key Technical Innovations
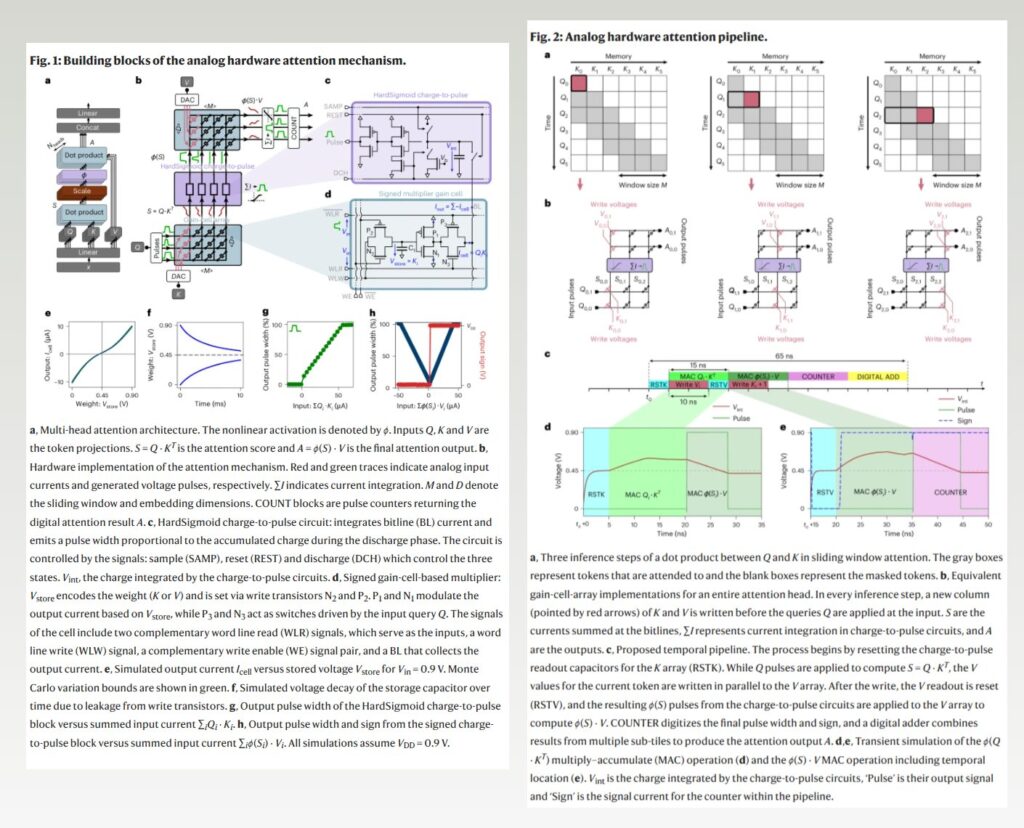
1. Gain Cell Technology The system uses emerging charge-based memories called gain cells, which can be efficiently written to store new tokens during sequence generation and enable parallel analog dot-product computation required for self-attention. Unlike traditional memory, gain cells can store information while simultaneously performing mathematical operations.
2. All-Analog Processing Rather than converting between digital and analog signals repeatedly, the new architecture performs attention computations entirely in the analog domain using innovative charge-to-pulse circuits. This avoids the power-intensive analog-to-digital converters that typically limit the efficiency of analog computing systems.
3. Hardware-Software Co-optimization The researchers developed specialized algorithms to adapt pre-trained models like GPT-2 to work with the non-ideal characteristics of analog hardware, achieving comparable accuracy without training from scratch.
Unprecedented Performance Results
The performance improvements are staggering:
Speed Improvements:
- 7,000x faster than Nvidia Jetson Nano
- 300x faster than Nvidia RTX 4090
- 100x faster than Nvidia H100
Energy Efficiency Gains:
- 40,000x more energy efficient than Jetson Nano
- 90,000x more energy efficient than RTX 4090
- 70,000x more energy efficient than H100
Our architecture reduces attention latency and energy consumption by up to two and four orders of magnitude, respectively, compared with GPUs, marking a substantial step toward ultrafast, low-power generative transformers.
Technical Architecture Deep Dive
Sliding Window Attention Implementation
The system implements sliding window attention, where only the most recent M tokens are retained in memory, preventing memory requirements from scaling with entire sequence length. To prevent the physical memory size from scaling with the entire sequence length, we employ a type of attention that is both causal and local: sliding window attention.
Multi-Level Integration
The architecture features:
- Gain cell arrays: Store keys and values while performing dot products
- Charge-to-pulse circuits: Convert analog currents to pulse-width modulated signals
- Sub-tiling: Multiple 64×64 arrays work in parallel for larger attention heads
- 3D stacking capability: Further reduces area requirements
Area Efficiency
The compact design achieves remarkable space efficiency. A single gain cell occupies approximately 1 μm², and the entire attention head requires only 0.5 mm² including control circuitry.
Overcoming Hardware-Software Compatibility Challenges
One major innovation addresses the challenge of adapting software models to analog hardware constraints. The researchers developed a three-step process:
- Intermediate Model Training: Fine-tune a model with hardware constraints but ideal linear operations
- Adaptation Algorithm: Map the model to non-linear gain cell characteristics
- Final Fine-tuning: Optimize for actual hardware performance
With our adaptation algorithm, our model achieves accuracy similar to a pre-trained GPT-2 model without having to train the model from scratch.
Real-World Performance Validation
The researchers validated their approach across standard language modeling benchmarks, demonstrating that their hardware-optimized models achieve performance comparable to traditional GPT-2 while delivering massive efficiency gains. The system maintains high accuracy on tasks including:
- Question answering (ARC datasets)
- Common-sense reasoning (WinoGrande, HellaSwag)
- Text comprehension (LAMBADA)
- Language modeling (WikiText-2)
Future Implications and Scalability
This breakthrough has profound implications for the future of AI deployment:
Edge Computing: The dramatic energy efficiency improvements make it feasible to run sophisticated LLMs on mobile devices and edge hardware without draining batteries.
Data Center Efficiency: Enhancing their efficiency is essential to reduce environmental impact and to keep pace with the exponentially growing size of AI models. This technology could significantly reduce the environmental footprint of AI data centers.
Scaling Potential: The researchers note that the KV-cache size grows modestly compared with the overall models’ parameters count. Our system could therefore be applied to larger networks with a moderate area footprint.
Technical Challenges and Solutions
Retention Time Management
Traditional gain cells have limited data retention, but the researchers address this through:
- OSFET-based gain cells with retention times of several seconds
- Efficient refresh mechanisms
- 3D integration possibilities for higher density
Precision and Accuracy
While analog computation introduces some precision limitations compared to digital processing, the adaptation algorithms successfully compensate for these effects, maintaining competitive accuracy on real-world tasks.
Industry Impact and Adoption Timeline
This research represents a significant step toward practical analog computing for AI workloads. While still in the research phase, the demonstrated performance improvements suggest this technology could:
- Enable new classes of AI-powered mobile applications
- Reduce data center power consumption for AI services
- Make advanced AI accessible in resource-constrained environments
- Accelerate the development of real-time AI applications
Conclusion: A Paradigm Shift in AI Hardware
This work demonstrates hardware-algorithm co-optimization achieving low latency and energy consumption while maintaining high model accuracy. In addition, it highlights the promise of IMC with volatile, low-power memory for attention-based neural networks, marking an important step toward ultrafast, energy-efficient generative AI.
The combination of 100x speed improvements and 10,000x energy efficiency gains represents one of the most significant hardware advances in AI processing. As this technology matures and moves toward commercial implementation, it could fundamentally reshape how and where AI models are deployed, making powerful language models accessible in scenarios previously impossible due to power and speed constraints.
For the AI industry, this breakthrough signals a future where the current trade-offs between model sophistication and practical deployment may no longer apply, opening new frontiers for AI applications across every sector of the economy.
This research was published in Nature Computational Science and represents collaborative work between multiple research institutions focusing on hardware-software co-design for energy-efficient AI systems.

