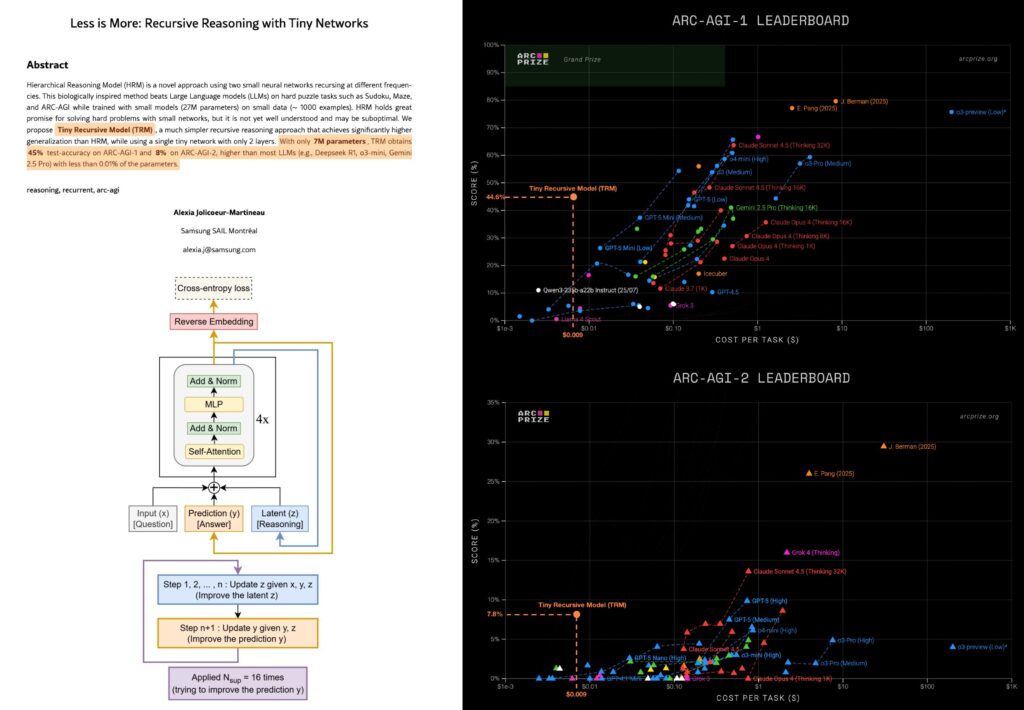
The TRM (Tiny Recursive Model) paper is turning heads — and for good reason. It absolutely crushes the Pareto frontier on benchmarks like ARC AGI 1 & 2, Sudoku, and Maze solving — all at an estimated cost of less than $0.01 per task, and a total training cost under $500 on just two H100 GPUs for two days.
Here’s what makes it wild: TRM trained on only 160 examples from ConceptARC, and at test time, it runs 1,000 augmented variations of each task, choosing the most common answer. It embeds a fixed shape of the task directly into the input — a compact, clever structure that gives it reasoning depth without scale.
This flips the script on how we think about AI progress. Instead of chasing ever-larger models, TRM shows that small, recursive architectures can outperform giants — at a fraction of the cost.
The implications for the industry are massive:
Most companies rely on general-purpose LLMs and complex prompting for every task. But for well-defined, repetitive jobs — like PDF data extraction, time-series forecasting, or structured report generation — tiny, specialized models could be cheaper, faster, and even more accurate.
Startups could literally train sub-$1,000 micro-models to handle niche “fixed-length” tasks — creating proprietary tools that plug into general AI systems and own real IP in the process.
The message is clear: the future of AI might not just be bigger — it might be smaller, smarter, and recursive.