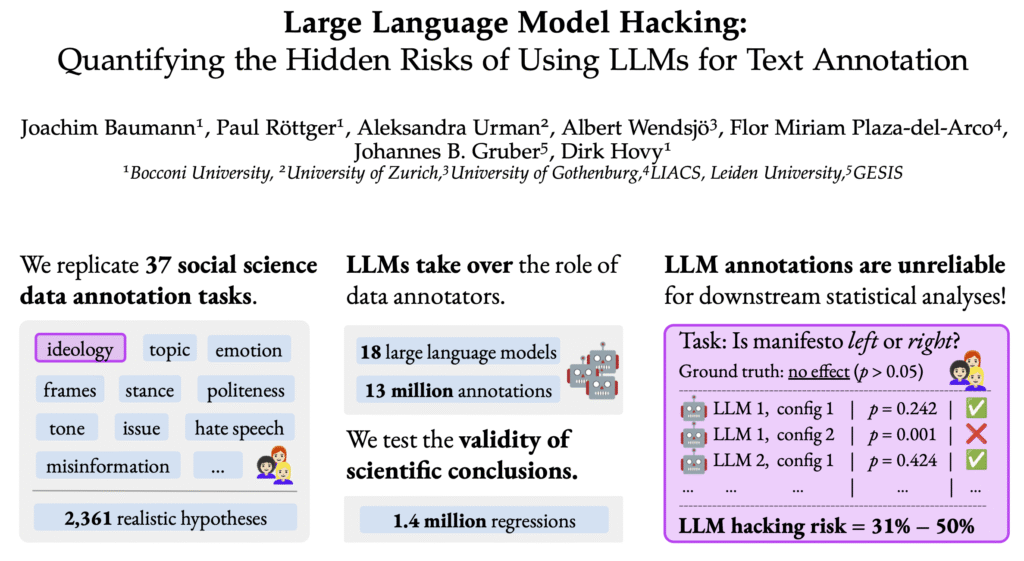
A groundbreaking research paper has exposed a critical vulnerability in modern scientific research that threatens the integrity of countless studies across multiple disciplines. The phenomenon, dubbed “LLM Hacking,” reveals how the widespread adoption of large language models for text annotation is inadvertently—and sometimes deliberately—producing misleading research results.
What is LLM Hacking?
LLM hacking refers to a disturbing pattern where research conclusions can be manipulated simply by changing which AI model is used, adjusting prompts, or modifying system settings—without altering the underlying data at all. This means that the same dataset can produce completely opposite conclusions depending on how researchers configure their AI annotation tools.
Unlike traditional research methods where conclusions are primarily determined by the data itself, LLM-based annotation introduces a layer of variability that can fundamentally alter study outcomes. The term “hacking” doesn’t necessarily imply malicious intent; rather, it describes how easily research results can be influenced by technical choices that seem minor but have major consequences.
The Scale of the Problem
The research team conducted an extensive analysis of 37 real research tasks using 18 different language models to quantify the scope of this issue. Their findings are alarming: incorrect results occurred in approximately 31% to 50% of cases when using LLM annotation compared to human-generated labels.
These aren’t minor discrepancies or edge cases. The errors include:
Missing Real Effects: Studies failing to detect genuine patterns that exist in the data, leading to false negative conclusions that could dismiss important findings.
Fabricating Non-Existent Effects: AI systems detecting patterns that aren’t actually present, creating false positive results that suggest relationships or phenomena that don’t exist.
Directional Errors: Correctly identifying that an effect exists but getting the direction wrong—for example, concluding that a treatment helps when it actually harms, or vice versa.
Magnitude Distortion: Dramatically over- or under-estimating the size of real effects, leading to conclusions about practical significance that are completely incorrect.
Why Social Sciences Are Particularly Vulnerable
The research identifies social science disciplines as particularly susceptible to LLM hacking vulnerabilities. This heightened risk stems from the statistical thresholds commonly used in these fields, where many studies operate near traditional significance cutoffs.
In social science research, studies often examine subtle effects that hover near statistical significance boundaries. When LLM annotation introduces additional variability, it can easily push results from one side of the significance threshold to the other, fundamentally changing the study’s conclusions.
This creates a perfect storm where small technical decisions about AI configuration can determine whether a study supports or refutes a hypothesis, regardless of what the data actually shows.
The Illusion of Big Data
One of the most counterintuitive findings challenges the assumption that more data automatically leads to better results. The researchers demonstrate that 100 carefully collected human annotations can be more reliable than 100,000 LLM-generated labels, particularly when it comes to avoiding false discoveries.
This finding strikes at the heart of modern research practices, where the apparent ease and cost-effectiveness of generating massive datasets using AI has led many researchers to prioritize quantity over quality. The study suggests that this approach may be fundamentally flawed, trading accuracy for volume in ways that compromise research integrity.
The implications extend beyond individual studies to entire research programs built on the assumption that AI-generated annotations are equivalent to or better than human judgment. Fields that have rapidly adopted LLM annotation may need to reconsider their methodological foundations.
The Failure of Post-Hoc Corrections
Recognizing the potential for AI annotation errors, some researchers have attempted to implement correction methods that adjust results after the initial analysis. However, the study reveals that these approaches don’t actually solve the underlying problem.
Post-hoc corrections create a statistical trade-off where reducing one type of error inevitably increases another. While researchers might successfully eliminate some false positives, they simultaneously increase the rate of false negatives, or vice versa. This creates an illusion of improvement while potentially making the overall problem worse.
The failure of correction methods highlights the fundamental nature of the LLM hacking problem: it’s not a simple bias that can be mathematically adjusted away, but rather a systematic instability in the annotation process itself.
The Gaming Potential
Perhaps the most concerning aspect of LLM hacking is how easily it can be exploited for deliberate result manipulation. The researchers demonstrate that someone seeking a particular outcome can achieve it simply by trying different models, prompts, or settings until they obtain their desired result.
This “researcher degrees of freedom” problem is amplified exponentially by the numerous configuration options available when using AI annotation systems. A researcher could legitimately try dozens of different approaches and simply report the one that supports their preferred conclusion, creating an appearance of scientific rigor while actually engaging in sophisticated result manipulation.
The ease of this process means that even well-intentioned researchers might unconsciously engage in this behavior, trying different AI configurations until they find results that seem “reasonable” based on their expectations, without realizing they’re compromising the study’s validity.
Real-World Examples and Case Studies
The paper documents numerous instances where identical datasets produced dramatically different conclusions based solely on AI annotation choices. In some cases, studies using one model configuration found strong positive effects, while the same data analyzed with a different setup showed equally strong negative effects.
These examples aren’t hypothetical scenarios but real research tasks that demonstrate how LLM hacking can occur in practice. The variability observed across different AI systems suggests that many published studies using LLM annotation may contain conclusions that are essentially arbitrary, determined more by technical choices than by genuine data patterns.
Implications for Research Integrity
The LLM hacking phenomenon raises serious questions about the integrity of research that relies heavily on AI annotation. Academic journals, funding agencies, and research institutions may need to reconsider how they evaluate studies that use these methods.
Current peer review processes typically focus on traditional methodological concerns but may not adequately address the unique vulnerabilities introduced by AI annotation systems. Reviewers might need specialized training to identify and evaluate LLM hacking risks in submitted research.
Industry and Applied Research Consequences
Beyond academic research, LLM hacking threatens the reliability of applied research in industry, policy, and other practical domains. Companies making strategic decisions based on AI-annotated market research, policy makers relying on automated content analysis, and organizations using AI for performance evaluation could all be affected by these systematic reliability issues.
The problem is particularly acute because the apparent sophistication and scale of AI-generated analysis can create false confidence in results. Decision-makers may be more likely to trust conclusions supported by analysis of massive datasets, not realizing that the underlying annotation process is fundamentally unstable.
Recommended Solutions and Best Practices
The research suggests several approaches for mitigating LLM hacking risks:
Human Validation: Maintaining human annotation for critical validation sets, even when using AI for the bulk of annotation work.
Multi-Model Consensus: Using multiple different AI systems and requiring agreement across models before drawing conclusions.
Transparency Requirements: Fully documenting all AI configuration choices, including failed attempts, to prevent selective reporting.
Stability Testing: Evaluating result stability across different reasonable configuration choices before finalizing conclusions.
Conservative Thresholds: Applying more stringent statistical thresholds when using AI annotation to account for additional uncertainty.
The Need for New Standards
The LLM hacking problem suggests that the research community needs new methodological standards specifically designed for AI-assisted research. Traditional research guidelines assume that annotation processes are relatively stable and consistent, but AI systems violate these assumptions in fundamental ways.
Professional organizations, journals, and funding agencies may need to develop specific protocols for evaluating and reporting research that uses AI annotation. These standards should address both the technical aspects of AI configuration and the broader methodological implications for study design and interpretation.
Future Research Directions
The discovery of LLM hacking opens numerous avenues for future investigation:
Stability Metrics: Developing quantitative measures of result stability across different AI configurations.
Robustness Testing: Creating systematic approaches for evaluating how sensitive research conclusions are to AI annotation choices.
Hybrid Approaches: Exploring optimal combinations of human and AI annotation that maximize both efficiency and reliability.
Detection Methods: Developing automated systems to identify potential LLM hacking in published research.
Long-Term Implications for Science
The LLM hacking phenomenon represents more than just a technical problem—it highlights fundamental questions about the role of AI in scientific research. As AI systems become more sophisticated and widely adopted, the research community must grapple with how to maintain scientific rigor while leveraging these powerful tools.
The challenge isn’t simply avoiding AI annotation entirely, but rather developing mature frameworks for using these systems responsibly. This requires understanding both their capabilities and their limitations, and designing research practices that account for their unique characteristics.
Conclusion: A Call for Methodological Reform
The discovery of LLM hacking serves as a critical wake-up call for the research community. The apparent convenience and power of AI annotation systems have led to widespread adoption without adequate consideration of their methodological implications.
Moving forward, researchers, institutions, and publishers must work together to develop new standards and practices that preserve research integrity in an AI-augmented world. This includes not only technical solutions but also cultural changes in how the research community approaches and evaluates AI-assisted studies.
The stakes are high: the credibility of scientific research depends on maintaining rigorous standards even as the tools and methods of investigation evolve. By acknowledging and addressing the LLM hacking problem now, the research community can work toward solutions that harness the benefits of AI while preserving the fundamental principles of reliable scientific inquiry.
The paper’s findings should serve as a catalyst for broader discussions about research methodology, peer review standards, and the responsible integration of AI tools in scientific investigation. Only through such comprehensive reform can the research community ensure that the AI revolution enhances rather than undermines the pursuit of knowledge.

