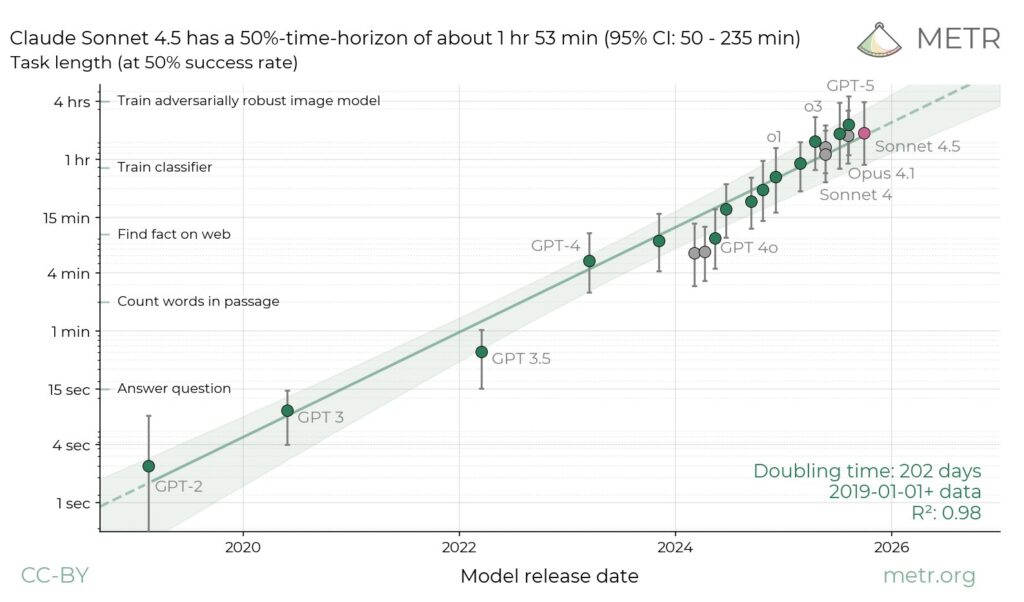
New benchmarks show Claude Sonnet 4.5 achieving a 50% success rate on multi-step software engineering tasks — with an average time horizon of ~1 hour 53 minutes (CI: 50–235 min).
That’s a 66% improvement in duration compared to Sonnet 4, a statistically significant leap in sustained reasoning and task persistence.
Here’s how it stacks up 👇
- 🔹 Sonnet 4.5 > Sonnet 4 by a large margin
- 🔹 Sonnet 4.5 ≈ Opus 4.1 (no significant difference)
- 🔹 Still slightly behind the longest-lasting model overall
The takeaway: Claude 4.5 marks a clear step forward in long-horizon reasoning — a key benchmark for real-world software engineering and autonomous agent workflows.

